A course “Software Evolution” in Göttingen.
Table of contents
- Data and Sources
- Mining Software Repositories
- Static Analysis, Metrics and Code Smells
- Clones
- Visualization and Understanding
- Defect Prediction
- Simulation of Software Evolution
Data and Sources
Version Control System
Git is one of the most famous and popular ones now.
Mining Software Repositories
RepositoryHandler is a python library for handling code repositories through a common interface.
With RepositoryHandler, you can use the tool CVSAnalY to extract information from the source code repository and store it into a database.
git clone https://github.com/MetricsGrimoire/RepositoryHandler.git
git clone https://github.com/MetricsGrimoire/CVSAnalY.git
git clone <Your project in git>
Before using it, the following env variables need to be set:
export PATH=$PATH:`pwd`/CVSAnalY
export PYTHONPATH=$PYTHONPATH:`pwd`/RepositoryHandler
Run CVSAnalY: (URI is where you put your git project.)
cvsanaly2 --db-driver sqlite <URI>
Browse the database:
sqlite3 cvsanaly
sqliteman cvsanaly
Database Schema Overview:
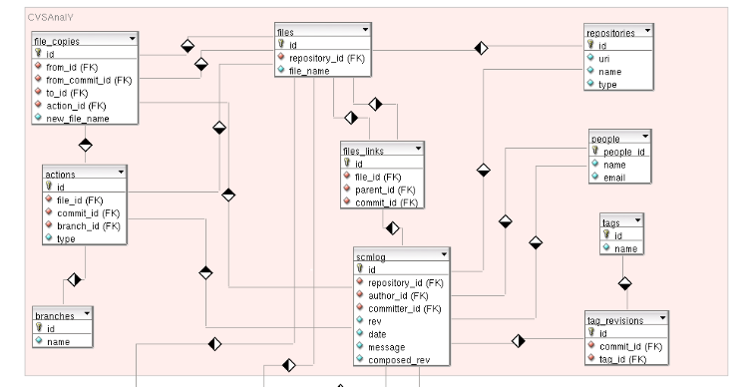
For example, count the number of commits per developer.
SELECT trim(p.name) as name, count(distinct s.id) as number_of_commits_people
FROM people as p
LEFT JOIN scmlog as s
ON p.id = s.committer_id
GROUP BY trim(p.name)
ORDER BY number_of_commits_people DESC
;
Find out how often files have been changed.
SELECT f.id, f.file_name, count(distinct a.id) as number_of_commits_file --,count(distinct s.id)
FROM files as f
INNER JOIN actions as a
ON f.id = a.file_id
AND a.type='M'
GROUP BY f.id, f.file_name
ORDER BY number_of_commits_file DESC
;
Static Analysis, Metrics and Code Smells
InFamix is a free static analysis tool for Java and C/C++ code. Note that as of April 2016 the company is no longer in business.
Use inFamix to do some trend analysis or hot spot analysis.
Run inFamix:
export PATH=$PATH:`pwd`/inFamix/
inFamix -lang cpp -path [URI] -mse ./[filename].mse
Identify minimum, maximum and average values:
cat [filename].mse | grep "(LOC " | sort
cat [filename].mse | grep "(LOC " | sed 's/[ |\t]//g' | sed 's/(LOC//g' | sed 's/)//g' | sort -n | head
cat [filename].mse | grep "(LOC " | sed 's/[ |\t]//g' | sed 's/(LOC//g' | sed 's/)//g' | awk '{ sum += $1 ; i+=1 } END { print sum/i }'
Some Metric Abbreviations
| Name | Granularity | Description |
|---|---|---|
| NOCHLD | Class | Number of Children |
| NOM | Class | Number of Methods |
| NOA | Class | Number of Attributes |
| StartLine | Method | Starting Line |
| EndLine | Method | Ending Line |
| LOC | Method | Lines of Code |
| LOCOMM | Method | Lines of Comments |
| NOPAR | Method | Number of Parameters |
Clones
DuDe is a free text-based, language independent clone detector. It supports three comparison strategies based on exact matching, Levenshtein distace, and token distance. Additional parameters can be used to tune the minimum duplication size, line bias (maximum number of lines between matching chunks), and the minimum exact chunk size. The GUI version of DuDe does not allow filtering of uninteresting files.
Some important parameters:
- maximum lines between (LB)
- minimum size of duplication chain (SDC)
- minimum size of exact chunk (SEC)
About Tests and Changes
TBC.
Visualization and Understanding
CodeCity is an integrated environment for software analysis, in which software systems are visualized as interactive, navigable 3D cities. The classes are represented as buildings in the city, while the packages are depicted as the districts in which the buildings reside. The visible properties of the city artifacts depict a set of chosen software metrics, as in the polymetric views of CodeCrawler.
Run a demo:
<codecity_path>/codecity/vw7.10.1pul/bin/linux86/visual <codecity_path>/codecity/codecity-image/codecity.im
In order to create a city, you need to import model from a MSE file which could be produced by the tool iPlasma.
Run iPlasma:
<iPlasma_path>/iPlasma/insider.sh -lang java -path <project> -mse <filename>.mse
 (http://wettel.github.io/pics/codecity_screenshot.png)
(http://wettel.github.io/pics/codecity_screenshot.png)
Gephi is a network analysis and visualization tool.
Defect Prediction
Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. It is also well-suited for developing new machine learning schemes.
Simulation of Software Evolution
There is a simulation project which is developed with Repast Simphony.
TBC.
blog comments powered by Disqus