Introduction
Before reading it, please read the warnings in my blog Learning Python: Web Scraping.
Different from Beautiful Soup or Scrapy, pyspider is a powerful spider (web crawler) system in Python:
- Write script in Python
- Powerful WebUI with script editor, task monitor, project manager and result viewer
- MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL with SQLAlchemy as database backend
- RabbitMQ, Beanstalk, Redis and Kombu as message queue
- Task priority, retry, periodical, recrawl by age, etc…
- Distributed architecture, Crawl Javascript pages, Python 2&3, etc…
Installation and Start
Use pip to install it:
pip install pyspider
Start it with the command below or run the run.py in the module directory:
python -m pyspider.run
Perhaps you might meet the error below:
Traceback (most recent call last):
File "run.py", line 757, in <module>
main()
File "run.py", line 754, in main
cli()
...
ValueError: Invalid configuration:
- Deprecated option 'domaincontroller': use 'http_authenticator.domain_controller' instead.
There are two solutions to solve this error (See in Error to start webui service).
Change the line 209 in the file pyspider/webui/webdav.py (almost the end of the file):
#'domaincontroller': NeedAuthController(app),
'http_authenticator': {
'HTTPAuthenticator':NeedAuthController(app),
},
Or you can change the version of wsgidav (I do not recommend this one option since it already published a new version 3.x).
pip install wsgidav==2.4.1
After that, you could visit http://localhost:5000/ to use the system.
And, in the directory where you start pyspider, there will be a directory data that is auto-generated and stores the databases of projects, tasks and results.
Get more help information with:
python3 -m pyspider.run --help
Starting Scraping
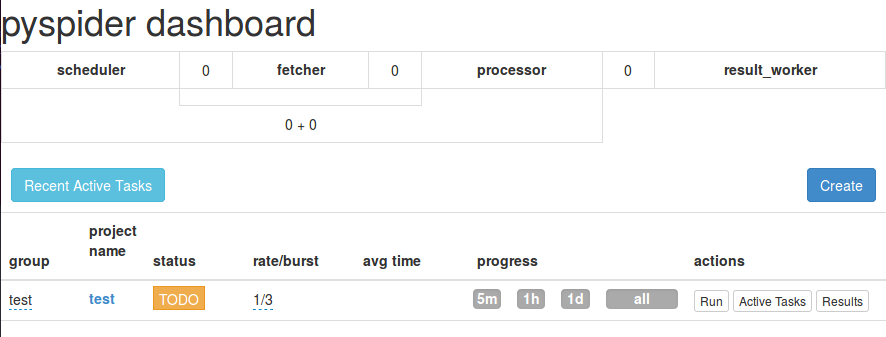
Creating a New Project
For the first time, there are no projects in the page.
You need to create a new one by clicking the “Create” button.
Input the project name and the URL you want to scrap:
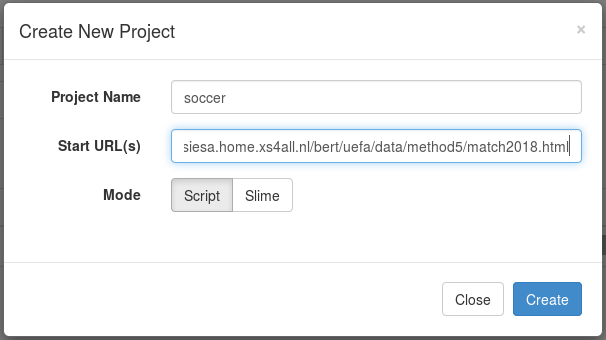
Click the “Create” button and enter the script editing page:
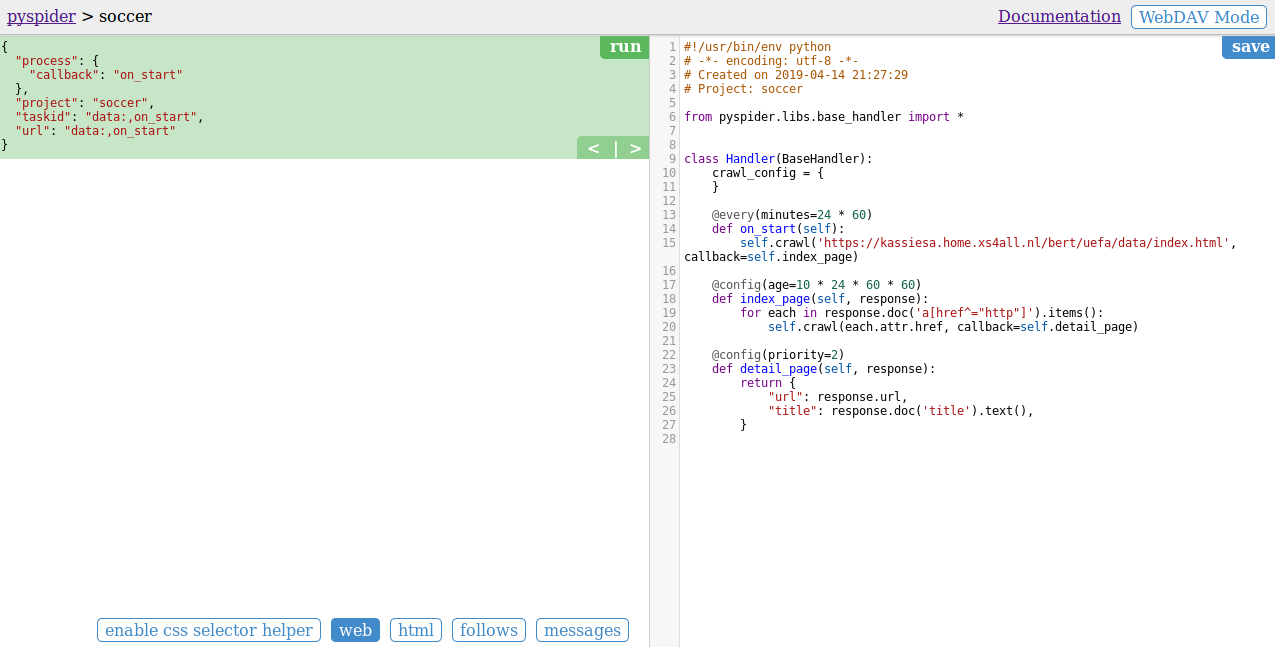
On the right panel, it is an auto-generated sample script:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-04-14 21:27:29
# Project: soccer
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
def on_start(self)is the entry point of the script. It will be called when you click the run button on dashboard.self.crawl(url, callback=self.index_page)is the most important API here. It will add a new task to be crawled. Most of the options will be spicified via self.crawl arguments.def index_page(self, response)get aResponseobject.response.docis a pyquery object which has jQuery-like API to select elements to be extracted.def detail_page(self, response)return a dict object as result. The result will be captured intoresultdbby default. You can overrideon_result(self, result)method to manage the result yourself.
Other configuration:
@every(minutes=24*60, seconds=0)is a helper to tell the scheduler that on_start method should be called everyday.@config(age=10 * 24 * 60 * 60)specified the default age parameter of self.crawl with page type index_page (when callback=self.index_page). The parameter age* can be specified via self.crawl(url, age=102460*60) (highest priority) and crawl_config (lowest priority).age=10 * 24 * 60 * 60tell scheduler discard the request if it have been crawled in 10 days. pyspider will not crawl a same URL twice by default (discard forever), even you had modified the code, it’s very common for beginners that runs the project the first time and modified it and run it the second time, it will not crawl again (read itag for solution)@config(priority=2)mark that detail pages should be crawled first.
Running Script
If you have modified the script, then click the “save” button.
Click the green “run” button on the left panel.
After that, you will find a red 1 above follows:
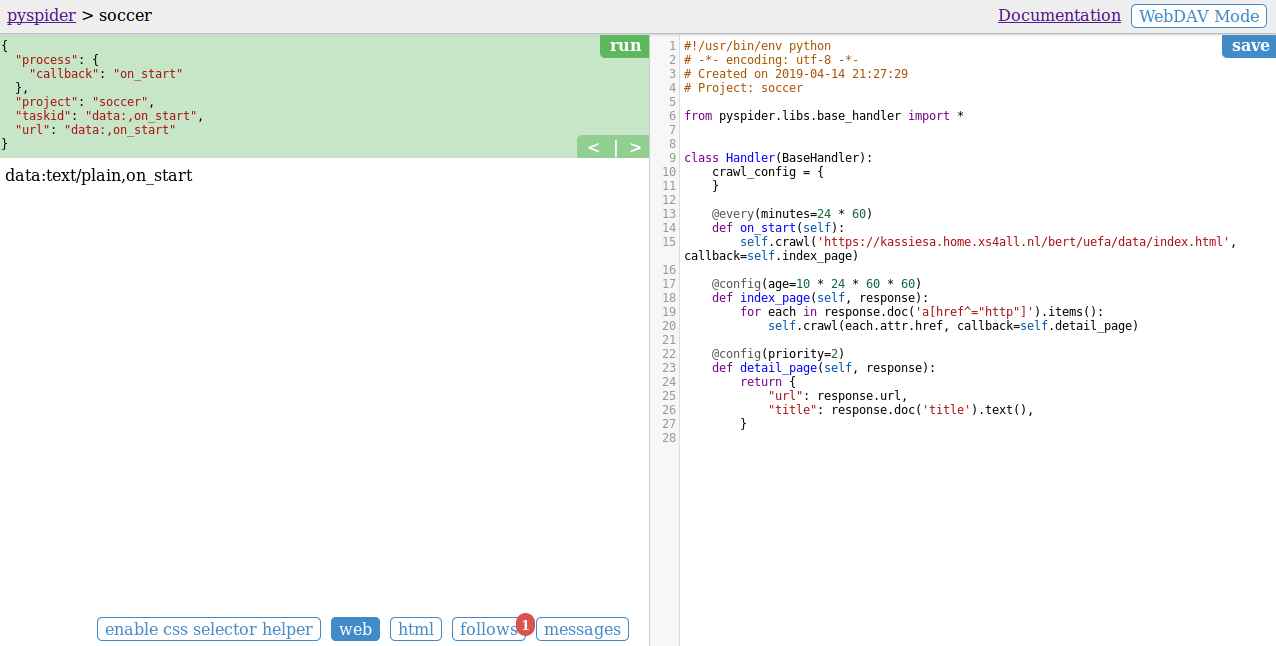
Click the “follows” button to switch to the follows panel.
It lists an index page.
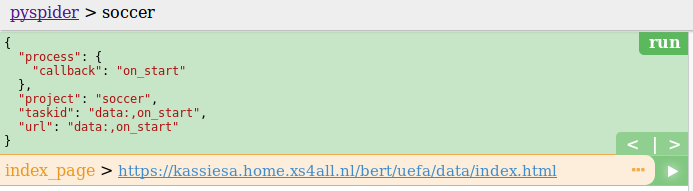
Click the green play button on the right of the URL (this will invoke the index_page method).
It will list all the URLs in the panel:
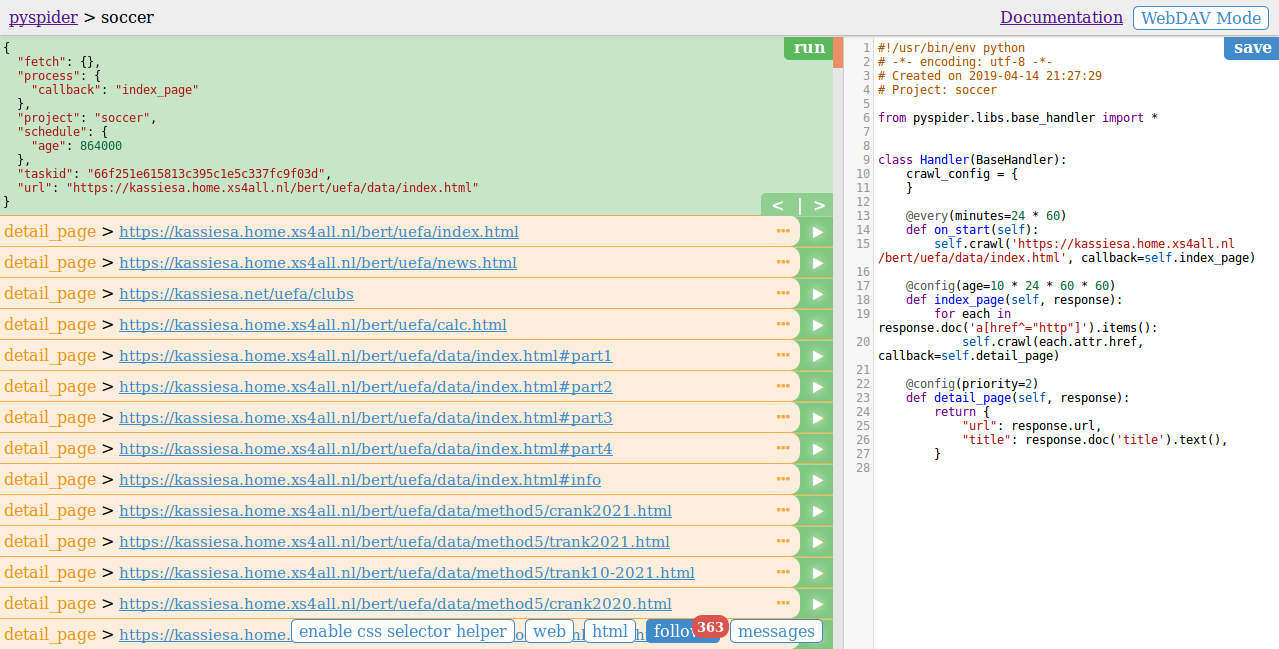
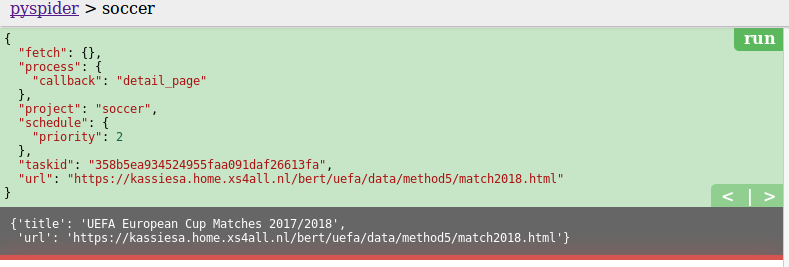
We could choose any one of the detail pages and click the green play button on the right (this will invoke the detail_page method).
It will show the final result.
In this example, we get the title and URL in json format.
Project Management
Back to the dashboard, you will find the project that is new created.
Change the status of the project from “TODO” to “RUNNING”:


Click the “run” button.
Then the project will start to run:

The output log in the background:
[I 190507 15:38:56 tornado_fetcher:188] [200] soccer:on_start data:,on_start 0s
[I 190507 15:38:57 processor:202] process soccer:on_start data:,on_start -> [200] len:8 -> result:None fol:1 msg:0 err:None
[I 190507 15:38:57 scheduler:906] task done soccer:on_start data:,on_start
[I 190507 15:38:57 scheduler:808] new task soccer:66f251e615813c395c1e5c337fc9f03d https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html
[I 190507 15:38:57 scheduler:965] select soccer:66f251e615813c395c1e5c337fc9f03d https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html
...
[I 190507 15:39:24 scheduler:586] in 5m: new:2,success:1,retry:1,failed:0 soccer:2,1,1,0
[I 190507 15:39:47 scheduler:965] select soccer:66f251e615813c395c1e5c337fc9f03d https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html
[I 190507 15:39:50 tornado_fetcher:419] [200] soccer:66f251e615813c395c1e5c337fc9f03d https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html 2.53s
[I 190507 15:39:50 processor:202] process soccer:66f251e615813c395c1e5c337fc9f03d https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html -> [200] len:31226 -> result:None fol:363 msg:0 err:None
[I 190507 15:39:50 scheduler:906] task done soccer:66f251e615813c395c1e5c337fc9f03d https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html
[I 190507 15:39:50 scheduler:808] new task soccer:dac0abc97c5ac01df0b5b48d8a977fe4 https://kassiesa.home.xs4all.nl/bert/uefa/data/method4/trank2015.html
[I 190507 15:39:50 scheduler:808] new task soccer:4e48010d75659bf1a48a40b5f2029ca8 https://kassiesa.home.xs4all.nl/bert/uefa/data/method3/trank2008.html
...
[I 190507 15:46:48 tornado_fetcher:419] [200] soccer:15c43675f0da0685ba2674dcc200e900 https://kassiesa.home.xs4all.nl/bert/uefa/data/method4/crank2011.html 0.05s
[I 190507 15:46:48 processor:202] process soccer:15c43675f0da0685ba2674dcc200e900 https://kassiesa.home.xs4all.nl/bert/uefa/data/method4/crank2011.html -> [200] len:13654 -> result:{'title': fol:0 msg:0 err:None
[I 190507 15:46:48 result_worker:33] result soccer:15c43675f0da0685ba2674dcc200e900 https://kassiesa.home.xs4all.nl/bert/uefa/data/method4/crank2011.html -> {'title': 'UEFA Country Rankin
[I 190507 15:46:48 scheduler:586] in 5m: new:0,success:297,retry:0,failed:0 soccer:0,297,0,0
[I 190507 15:46:48 scheduler:906] task done soccer:15c43675f0da0685ba2674dcc200e900 https://kassiesa.home.xs4all.nl/bert/uefa/data/method4/crank2011.html
[I 190507 15:46:49 scheduler:808] new task soccer:on_finished data:,on_finished
[I 190507 15:46:49 scheduler:965] select soccer:on_finished data:,on_finished
[I 190507 15:46:50 tornado_fetcher:188] [200] soccer:on_finished data:,on_finished 0s
[I 190507 15:46:50 processor:202] process soccer:on_finished data:,on_finished -> [200] len:11 -> result:None fol:0 msg:0 err:None
[I 190507 15:46:50 scheduler:906] task done soccer:on_finished data:,on_finished
Click the “Results” button and check all the scraping results:
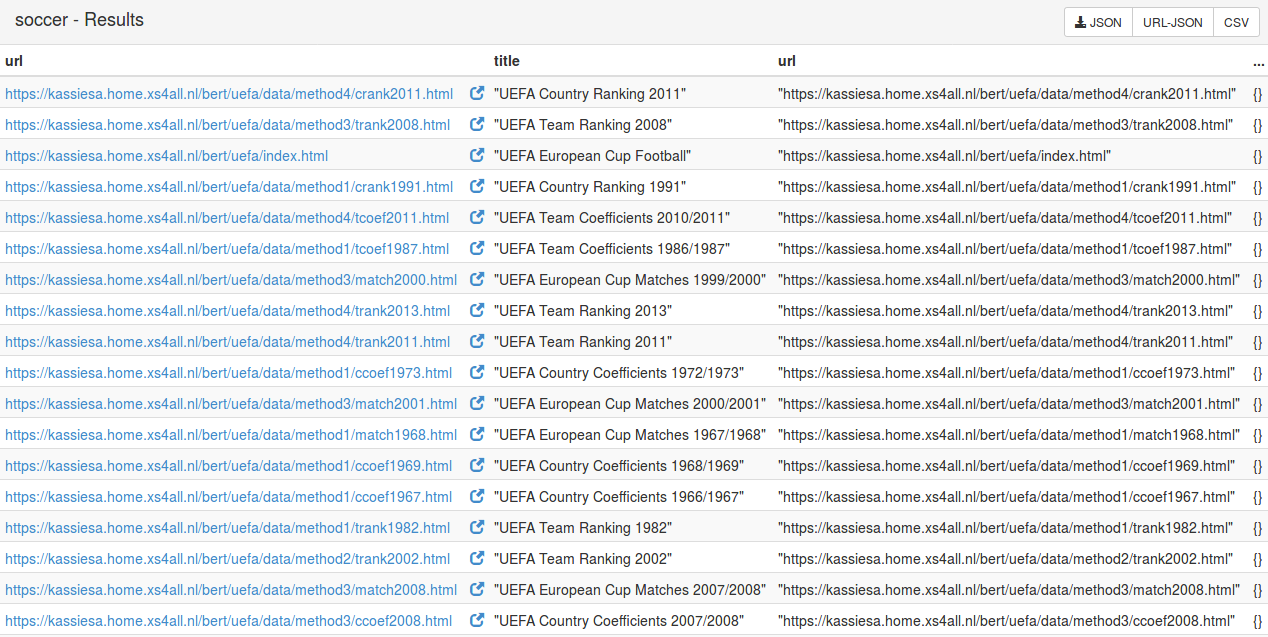
Click one of the results and the new page will show the result in detail.
Example
UEFA European Cup Coefficients Database lists links for matches, country ranking and club ranking since season 1955/1956. The sample program below extracts the match data from season 2004/2005 to season 2017/2018.
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://kassiesa.home.xs4all.nl/bert/uefa/data/index.html", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc("a[href^='http']").items():
if "method5/match" in each.attr.href or "method4/match" in each.attr.href:
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
games = {}
for table in response.doc(".t1").items():
game_type = table(".blue div").text()
games[game_type] = {}
stage_name = ""
for row in table("tr").items():
if row.attr.class_ == "yellow":
stage_name = row("div").text()
games[game_type][stage_name] = []
elif row.attr.class_ == "lgray":
match = []
for m in row("td").items():
match.append(m.text())
games[game_type][stage_name].append(match)
return games
Output looks like:
{'CHAMPIONS LEAGUE':
{'1st Qualifying Round': [['Víkingur', 'Far', "Trepça'89", 'Kos', '2-1', '4-1'],
['Hibernians FC', 'Mlt', 'FCI Tallinn', 'Est', '2-0', '1-0']
...
]
...
}
'EUROPA LEAGUE':
{
...
}
...
}
Further
Some web contents are becoming more complicated using some technology like AJAX. Then page looks different with it in browser, the information you want to extract is not in the HTML of the page. In this case, you will need the web browser developer tools(such as Web Developer Tools in Firefox or Chrome) to find the request with parameters by yourself.
Sometimes web page is too complex to find out the API request. It provides an option to use PhantomJS. To use PhantomJS, you should have PhantomJS installed. If you are running pyspider with all mode, PhantomJS is enabled if executable in the PATH.
More information about pyspider in detail can be found in pyspider Official Documentation or its GitHub.
References
blog comments powered by Disqus